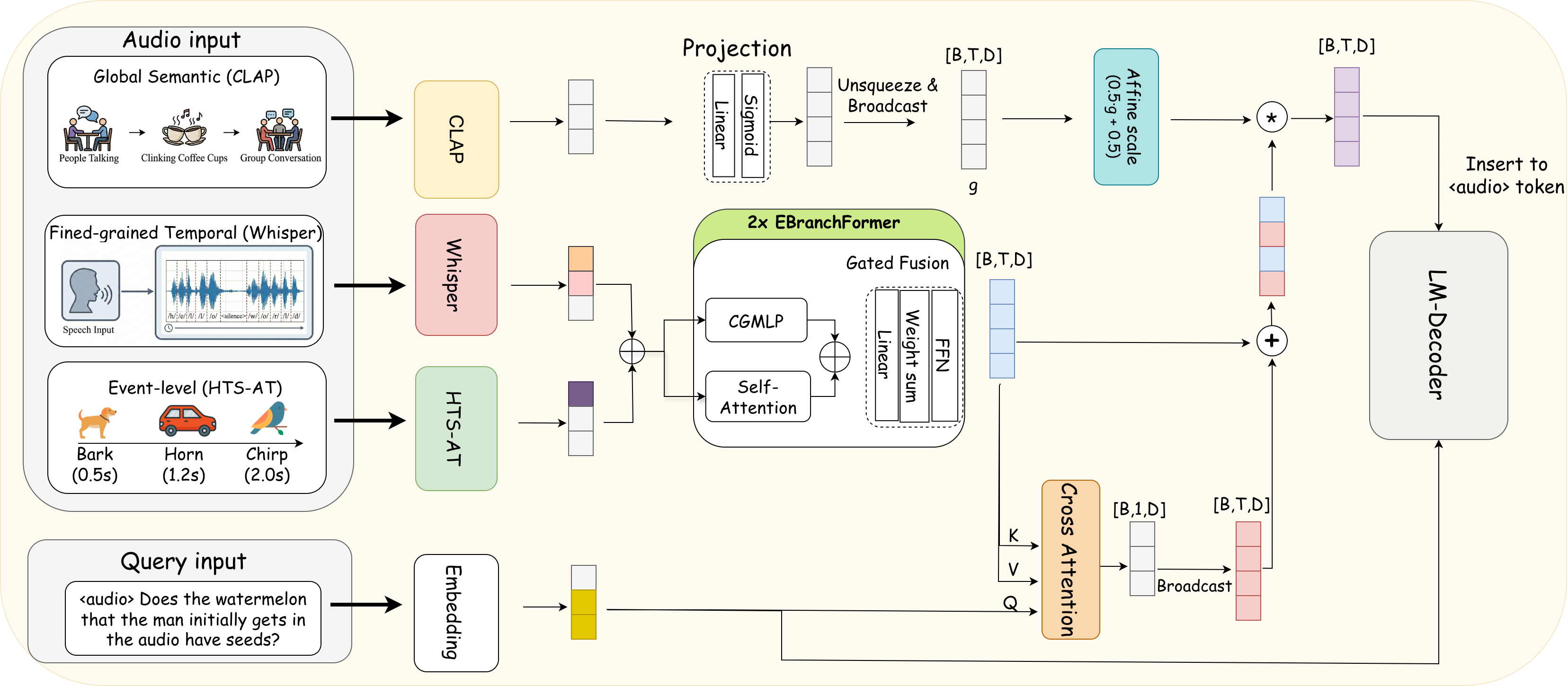
Current advancements in Audio Reasoning rely on massive Large Audio-Language Models (LALMs), hindering deployment in resource-constrained environments. We introduce TinyGiantALM, a compact 1.5B efficiency-oriented alternative. Instead of brute-force scaling, we propose an Instruction-Aware Feature Refinement framework using a Query-guided Projector and Semantic Gating to filter acoustic signals based on user intent.
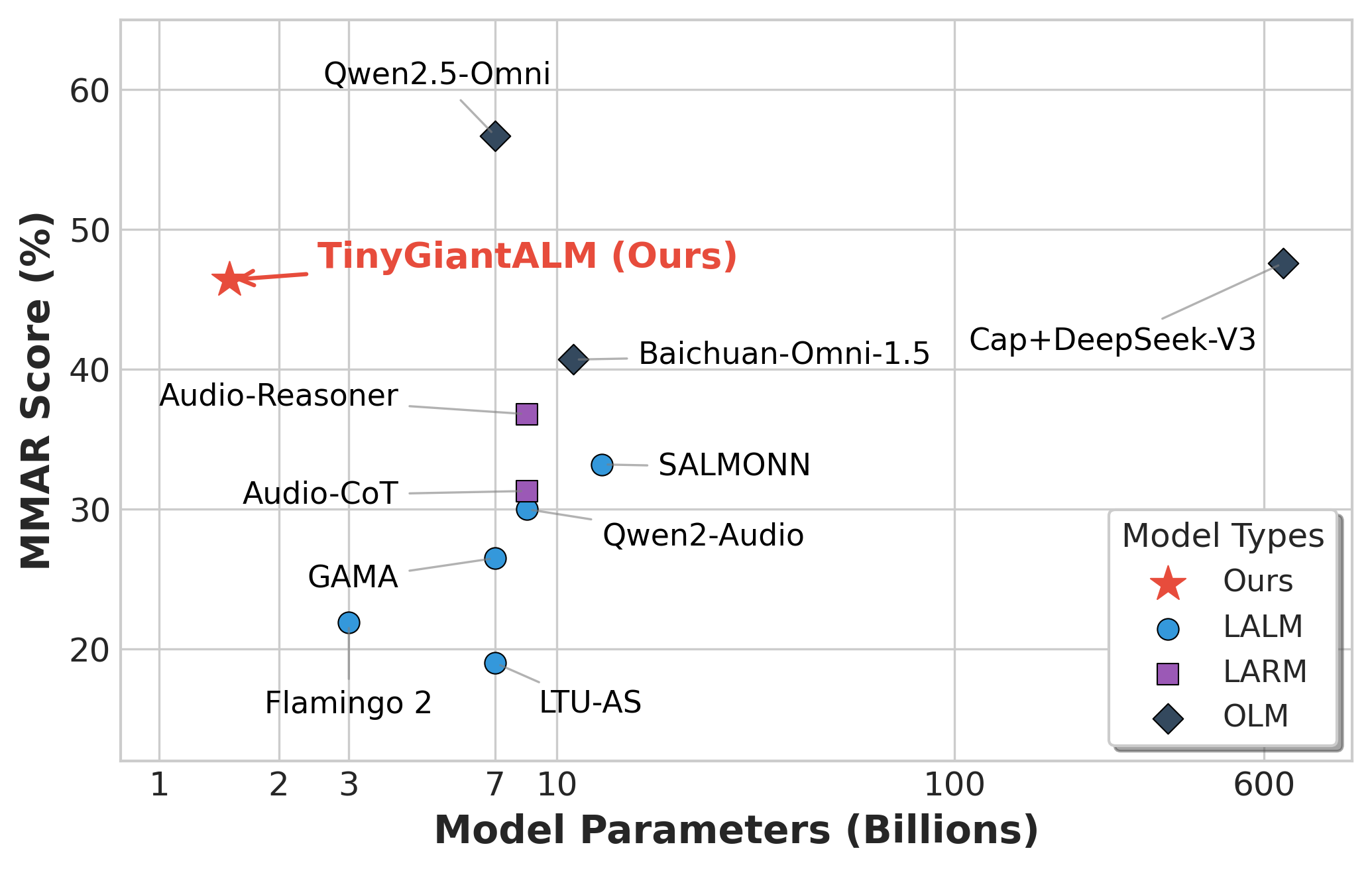
On the MMAR benchmark, TinyGiantALM achieves 46.4% zero-shot accuracy, significantly outperforming 7B-13B baselines. While a reasoning gap in logical narrative remains versus 30B+ models and certain trade-offs exist in overly dense or spatial scenes, our approach notably surpasses models up to 8x larger in disentangling mixed-modality environments.
These findings demonstrate that architectural precision offers a tangible pathway to secure robust perception capabilities on edge-friendly scales.